Automatisation de l’intégration d’un tableau de bord Databricks en utilisant GitHub Pages
Introduction
Ce document fournit un cadre technique pour intégrer un tableau de bord Databricks sur un site web externe en utilisant GitHub Actions et GitHub Pages. L’objectif principal est d’automatiser le processus de mise à jour et d’intégration des tableaux de bord Databricks, facilitant ainsi le partage et la visualisation des données.
Databricks est une plateforme unifiée d’analyse de données qui offre une solution complète pour l’ingénierie des données, la science des données collaborative, l’apprentissage automatique et l’analyse d’entreprise. L’une de ses fonctionnalités puissantes est Databricks Dashboards, qui permet aux utilisateurs de créer, visualiser et partager des visualisations de données interactives.
Dans ce projet, nous travaillerons avec le jeu de données nommé “DPE Logements existants (depuis juillet 2021)” disponible sur ADEME. DPE signifie “Diagnostic de Performance Energétique”. Pour une meilleure gestion, nous stockerons sur Databricks ces données sous forme de tables avec tous les champs en type chaîne de caractères, et d’autres manipulations de type de données seront effectuées via des requêtes SQL.
Pour plus de détails sur le schéma du jeu de données, veuillez-vous référer au site ADEME. Vous pouvez également consulter le dictionnaire de données disponible sur ce lien. Nous décrirons davantage le jeu de données dans la section dédiée “Cas d’utilisation : Utilisation de données ouvertes pour la visualisation de tableau de bord”.
Contexte technique et de développement
Lors du travail de recherche préliminaire, nous nous sommes posé la question : “En quoi Databricks est-il un avantage ou non pour construire et rendre disponible une visualisation de données par rapport à d’autres options possibles ?” Databricks offre plusieurs options pour le partage et la visualisation de données, chacune avec ses propres avantages et inconvénients. Nous présentons ci-dessous un tableau comparatif non exhaustif de ces avantages et inconvénients.
| Option | Avantages | Inconvénients |
| Databricks Notebooks | Supporte plusieurs langages (Python, SQL, Scala, R) Facile à partager et à collaborer |
Capacités de visualisation limitées
Pas idéal pour les tableaux de bord complexes |
| Databricks SQL Analytics | Interface SQL puissante
Capacités de visualisation avancées Requêtes et tableaux de bord programmés |
Limité à SQL |
| Databricks + Outils BI (par exemple, Tableau, Power BI) | Interface SQL puissante
Exploite les fonctionnalités avancées des outils BI Tableaux de bord riches et interactifs |
Nécessite une licence supplémentaire pour les outils BI
La configuration peut être complexe |
| Databricks + GitHub Pages (Jekyll) | Hébergement gratuit avec GitHub Pages
Flexibilité de Jekyll pour la personnalisation |
Nécessite une connaissance de la configuration de Jekyll et GitHub Pages |
L’objectif principal de ce projet est d’établir un cadre technique pour intégrer un tableau de bord Databricks dans un site web externe. Compte tenu des exigences et contraintes spécifiques de notre projet, nous avons trouvé que la combinaison de Databricks et GitHub Pages était la solution la plus appropriée. Cette approche nous permet d’exploiter les capacités des tableaux de bord Databricks et des GitHub Actions pour automatiser le processus de mise à jour et d’intégration des graphiques. Elle ne se contente pas de rationaliser le partage des informations de données, mais améliore également l’accessibilité et l’utilisabilité des visualisations de données fournies par les tableaux de bord Databricks. De plus, cette méthode nous permet d’intégrer un tableau de bord Databricks sans nécessairement partager les données ou donner accès à Databricks aux utilisateurs.
Cas d’usage : Utilisation de données ouvertes pour la visualisation de tableau de bord
Dans ce projet, nous utiliserons des données ouvertes disponibles sur le site français ADEME. Ce site donne accès à de grands ensembles de données contenant des données de Diagnostic de Performance Énergétique (DPE).
Le DPE est une mesure de l’efficacité énergétique des bâtiments en France. Il fournit une étiquette énergétique, allant de A (le plus efficace) à G (le moins efficace), et est obligatoire pour tous les bâtiments qui sont vendus ou loués en France.
L’ensemble de données que nous utiliserons contient des informations détaillées sur le DPE de divers logements à travers le pays. Cela inclut l’étiquette énergétique, l’année de construction, le type de système de chauffage, et bien plus encore.
Notre objectif est de créer un tableau de bord qui visualise ces données, fournissant des insights sur l’efficacité énergétique des logements en France. Par exemple, nous pourrions créer des visualisations montrant la distribution des bâtiments résidentiels en fonction de leurs étiquettes énergétiques, nous permettant de voir en un coup d’œil à quel point les logements sont économes en énergie.
Dans notre exploration de ce cas d’utilisation, nous créerons des visualisations dans Databricks en utilisant deux approches différentes. La première approche implique un workflow qui utilise une tâche SQL pour générer un tableau de bord. La deuxième approche, en revanche, emploie une tâche de notebook à la même fin.
Dans notre contexte spécifique, nous ajoutons diverses visualisations au tableau de bord pour mieux comprendre les données. Chaque visualisation fournit un aperçu unique de l’ensemble de données. Pour les deux approches que nous discuterons plus tard, nous ajouterons les visualisations suivantes.
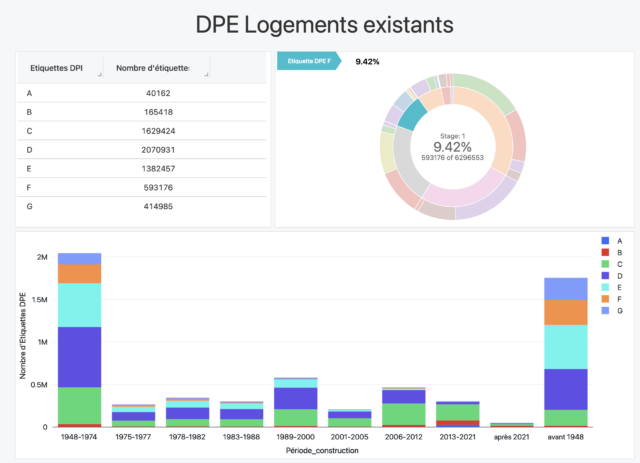
- Nombre total d’étiquettes_DPE : Ce diagramme à barres montre le nombre total d’Etiquettes_DPE pour chaque catégorie allant de A à G. Il donne un aperçu de la distribution des étiquettes de diagnostic de performance énergétique (DPE) dans l’ensemble de données.
- Distribution des étiquettes DPE et GES : Ce diagramme en éventail montre la distribution hiérarchique des étiquettes DPE et GES.
- Nombre d’étiquettes DPE par période de temps : Ce diagramme à barres empilées donne un aperçu de l’attribution des étiquettes sur une période de temps donnée.
Tout au long de ce document, nous comparerons ces deux méthodes en termes d’efficacité, de facilité d’utilisation et d’adaptabilité à nos besoins spécifiques. À la fin de notre exploration, nous déterminerons quelle approche est la plus adaptée à nos objectifs. Cette analyse comparative nous aidera non seulement à optimiser notre projet actuel, mais aussi à fournir des informations précieuses pour des projets similaires à l’avenir.
Pré-requis
Ce projet nécessite les éléments suivants :
- Un catalogue Databricks contenant la base de données source utilisée pour générer le tableau de bord.
- Un point de terminaison SQL sans serveur activé dans votre espace de travail Databricks.
- Databricks CLI1 installé et configuré dans votre environnement local.
- Un compte GitHub pour héberger le développement local et une familiarité avec GitHub Pages.
Limitations et défis
Ce projet a été entrepris avec un calendrier serré d’une seule semaine, ce qui a constitué une contrainte significative sur la profondeur de la recherche et de l’exploration que nous pouvions mener. Malgré cela, nous nous sommes efforcés de fournir une solution complète et pratique.
L’un des principaux défis auxquels nous avons été confrontés était l’automatisation de la création de tableaux de bord. Actuellement, les tableaux de bord Databricks sont principalement conçus pour être créés manuellement en utilisant l’interface utilisateur de Databricks. Cela a posé un obstacle dans notre quête d’automatisation. Cependant, nous avons exploré et présentons quelques alternatives pour définir un tableau de bord de manière programmatique. Bien que ces alternatives ne soient pas aussi directes que la création manuelle, elles offrent un point de départ pour automatiser ce processus et ouvrent des possibilités pour une exploration et une amélioration supplémentaire.
Analyse comparative : Approches de tâche SQL vs tâche de notebook
Les tableaux de bord Databricks représentent une fonctionnalité puissante qui permet aux utilisateurs de créer, de visualiser et de partager des visualisations personnalisées de leurs données. Ils offrent une manière flexible et interactive d’explorer et de présenter les insights de données. Dans notre quête pour automatiser les mises à jour des tableaux de bord Databricks, nous avons exploré deux approches distinctes : une basée sur une tâche SQL et l’autre sur une tâche de notebook.
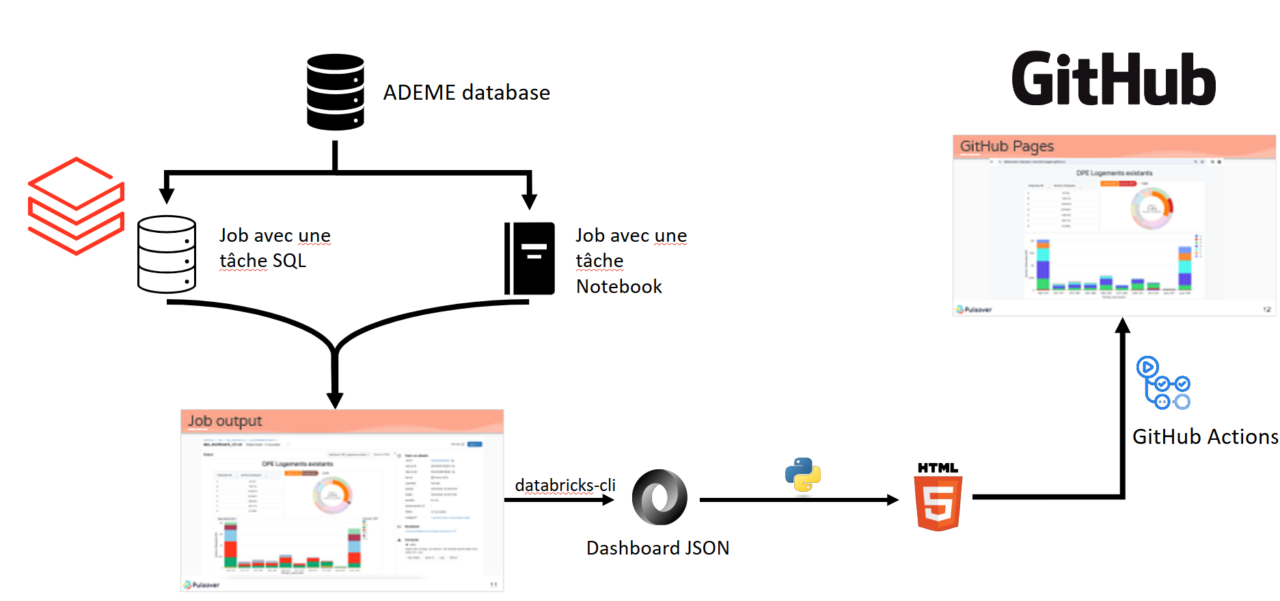
L’Approche de tâche SQL implique de définir un workflow avec une tâche SQL, dont la sortie est un tableau de bord que nous créons initialement manuellement. Dans cette approche, nous définissons d’abord les requêtes et leurs visualisations associées. Les développeurs peuvent définir toutes leurs requêtes dans un environnement local, puis les télécharger sur leur espace de travail en utilisant le CLI Databricks. Cela permet un contrôle de version des requêtes et une meilleure gestion du processus de développement. Nous recommandons de définir les requêtes comme des fichiers SQL, puis d’utiliser un script Python pour générer le JSON contenant les définitions des requêtes. Pour automatiser l’actualisation du tableau de bord, nous planifions ces requêtes en les attachant à un travail. Un avantage significatif de cette approche est l’utilisation d’un entrepôt SQL comme calcul, ce qui réduit les coûts car il élimine le besoin d’un cluster supplémentaire. Cependant, une limitation notable est que l’exportation du résultat de l’exécution (c’est-à-dire les paramètres du tableau de bord) de manière programmatique n’est prise en charge que pour les tâches de notebook, pas pour les tâches SQL.
L’image suivante offre une vue détaillée de la sortie d’une tâche SQL exécutée par un job Databricks. Elle met en avant les widgets créés et tous les détails standards de l’exécution de la tâche. Cette représentation visuelle donne un aperçu exhaustif de l’exécution de la tâche, incluant le statut de l’exécution, sa durée, et d’autres métriques pertinentes. C’est une capture de l’état du système au moment de l’exécution de la tâche, offrant des informations précieuses sur la performance et le résultat de la tâche SQL.
Et l’image ci-dessous présente le tableau de bord lui-même, le produit final de l’approche de tâche SQL. C’est une représentation visuelle des informations tirées de la tâche SQL. Le tableau de bord est conçu pour être intuitif, facilitant la compréhension et l’interprétation des données par les utilisateurs.
L’Approche de tâche de Notebook, d’autre part, implique de définir les mêmes requêtes dans un notebook attaché à un point de terminaison SQL. Nous ajoutons manuellement les mêmes visualisations pour créer un tableau de bord identique. Dans les deux cas, nous avons ajouté trois visualisations spécifiques. Ce notebook est ensuite programmé, ce qui donne lieu à un travail Databricks avec une tâche de notebook. Le principal avantage de cette approche est la possibilité d’exporter de manière programmatique une sortie d’exécution. Nous pouvons ensuite utiliser un script Python pour analyser les paramètres du tableau de bord et générer un fichier HTML contenant le tableau de bord. Ce fichier HTML peut être intégré dans une page GitHub, offrant une manière transparente de partager le tableau de bord. Cependant, un inconvénient notable est que chaque exécution de travail nécessite un nouveau cluster de travail, ce qui entraîne l’utilisation de ressources de calcul supplémentaires.
Il est important de noter que les visualisations sont mises à jour en exécutant leurs tâches correspondantes. Pour les besoins de cet article, la source de données avec laquelle nous travaillons est statique, ce qui signifie que les rafraîchissements n’incluront pas de nouvelles entrées. Cependant, dans un scénario réel où nous effectuons une tâche en continu, chaque fois que de nouvelles données entrent dans Databricks et que les deux tâches sont déclenchées, les tableaux de bord correspondants seront mis à jour pour prendre en compte les nouvelles données.
Résultats et comparaison des approches
Comme nous venons de le voir, alors que l’Approche de tâche SQL offre des avantages en termes de coûts et un meilleur contrôle de version pour les requêtes, l’Approche de tâche de Notebook offre une plus grande flexibilité pour l’automatisation et le partage. Le choix entre ces deux approches dépend des exigences spécifiques et des contraintes de votre projet.
Voici un tableau comparatif des avantages et des inconvénients de chaque approche :
| Approche | Avantages | Inconvénients |
| Tâche SQL | Économique (pas de cluster supplémentaire nécessaire),
Performance plus rapide |
Pas de support pour l’exportation, programmatique de la sortie d’exécution |
| Tâche de Notebook | Possibilité d’exporter de manière programmatique la sortie d’exécution, Intégration facile du tableau de bord dans des sites web externes | Chaque exécution de travail nécessite un nouveau cluster de travail, ce qui entraîne une utilisation supplémentaire des ressources de calcul, Performance plus lente par rapport à la tâche SQL |
En conclusion, si votre préoccupation principale est le coût et le contrôle de version pour les requêtes, l’Approche de tâche SQL pourrait être le meilleur choix. Cependant, si vous avez besoin d’une plus grande flexibilité pour l’automatisation, le partage et l’intégration de votre tableau de bord dans des sites web externes, l’Approche de tâche de Notebook serait plus appropriée.
Déployer le tableau de bord avec GitHub Pages
Une fois que nous avons obtenu les paramètres du tableau de bord en utilisant soit l’Approche de tâche SQL, soit l’Approche de tâche de Notebook, l’étape suivante consiste à déployer le tableau de bord. Une manière pratique et efficace de le faire est d’utiliser GitHub Pages.
Pour déployer notre tableau de bord, nous pouvons définir un flux de travail de déploiement de base qui utilise jekyll-build-pages, une simple action GitHub pour produire des artefacts de construction Jekyll compatibles avec GitHub Pages. Cette action prendra notre fichier HTML de tableau de bord que nous avons obtenu de manière programmatique et le publiera comme un site web sur GitHub Pages. Notre code définit un flux de travail qui comprend deux types d’événements, tous deux permettant des mises à jour du tableau de bord publié : workflow_dispatch et push. L’événement workflow_dispatch nous permet de déclencher manuellement une exécution de flux de travail à partir de l’onglet GitHub Actions, offrant une flexibilité lorsque nous voulons contrôler le moment du déploiement. D’autre part, l’événement push déclenche le flux de travail automatiquement chaque fois qu’un changement est validé sur une branche spécifique, garantissant que notre tableau de bord est toujours à jour avec les derniers changements de notre base de code.
Cette approche vous permet de partager facilement votre tableau de bord Databricks avec d’autres, sans qu’ils aient besoin d’accéder à votre espace de travail Databricks. Elle offre également les avantages du contrôle de version, car vos paramètres de tableau de bord et votre workflow de déploiement sont stockés dans un dépôt GitHub.
Conclusion
Dans ce projet, nous avons exploré deux approches pour automatiser la mise à jour des tableaux de bord Databricks : l’Approche de tâche SQL et l’Approche de tâche de Notebook.
L’Approche de tâche SQL offre des avantages en termes de coûts, un meilleur contrôle de version pour les requêtes, et une performance plus rapide. Cependant, elle ne supporte pas l’exportation programmatique de la sortie d’exécution. D’autre part, l’Approche de tâche de Notebook offre la possibilité d’exporter de manière programmatique la sortie d’exécution et d’intégrer facilement le tableau de bord dans des sites web externes, mais elle nécessite un nouveau cluster de travail pour chaque exécution, ce qui entraîne une utilisation supplémentaire des ressources de calcul et une performance plus lente par rapport à l’Approche de tâche SQL.
Nous avons également discuté de la manière de partager le tableau de bord mis à jour en utilisant GitHub Pages. Cette approche permet de partager facilement le tableau de bord Databricks sans que les autres aient besoin d’accéder à l’espace de travail Databricks. Elle offre également les avantages du contrôle de version, car les paramètres du tableau de bord et le workflow de déploiement sont stockés dans un dépôt GitHub.
En conclusion, automatiser la mise à jour des tableaux de bord avec Databricks SQL est un processus simple. Le choix entre l’Approche de tâche SQL et l’Approche de tâche de Notebook dépend des exigences spécifiques et des contraintes de votre projet. Quelle que soit l’approche choisie, le résultat est un tableau de bord entièrement automatisé, facilement partageable et contrôlé par version.